Few-Shot 6D Object Pose Estimation via Decoupled Rotation and Translation with Viewpoint Encoding
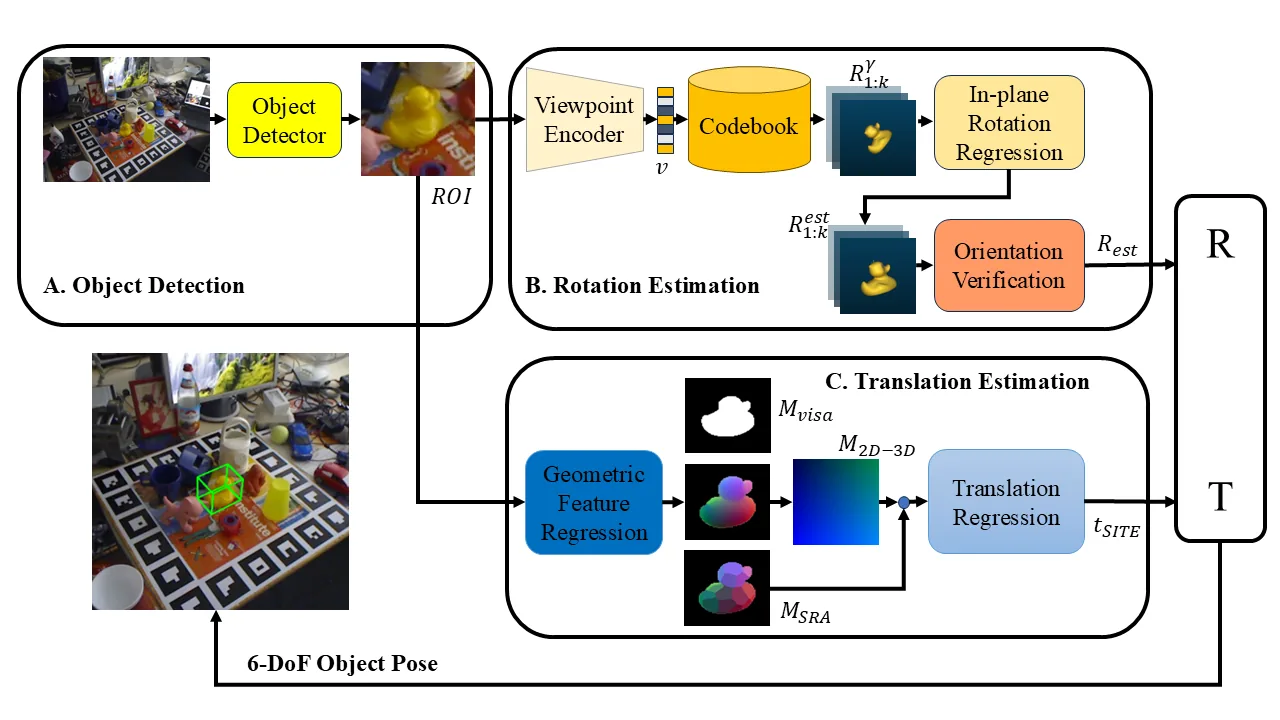
This work addresses few-shot monocular 6D object pose estimation by separating rotation and translation into two easier subproblems. Rotation is estimated through a viewpoint encoder and codebook retrieval trained from synthetic CAD-rendered views, while translation is estimated using geometry-aware dense correspondences inspired by GDR-Net.
This work appears in Electronics, 15(3):561.
Algorithm principle
The method decouples 6D pose into rotation estimation and translation estimation. For rotation, a viewpoint encoder maps object crops into a viewpoint embedding. Synthetic object views rendered from ShapeNet-style CAD models are stored in a codebook, allowing the system to retrieve coarse out-of-plane rotation candidates without requiring dense real pose annotations. An in-plane rotation regressor and orientation verification stage then refine the rotation estimate.
For translation, the pipeline predicts geometry-aware dense correspondences and mask-related geometric cues, then regresses the 3D translation so that the object projection agrees with the observed RGB image. This split design is especially useful in few-shot settings because rotation can be learned from synthetic view coverage, while translation is anchored by image geometry from a small amount of real data.
Visual evidence
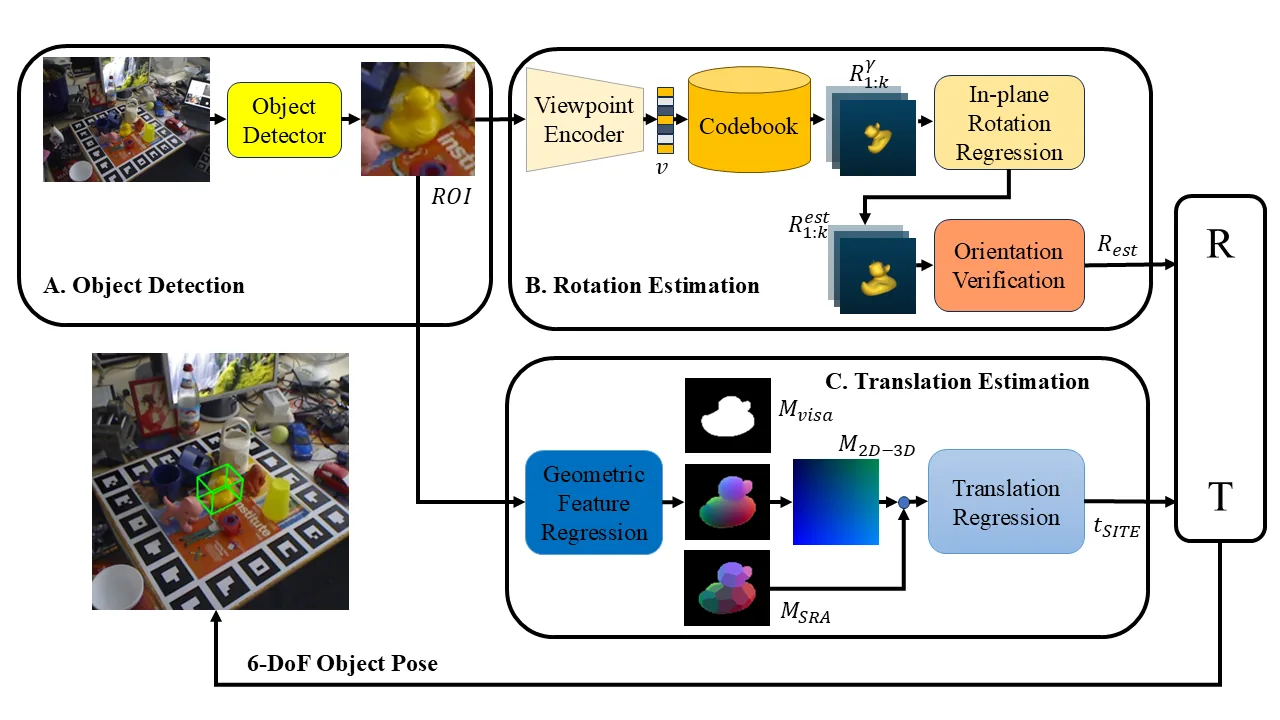
FS6D overview. The pipeline detects an object, estimates rotation through viewpoint-encoded retrieval and refinement, and estimates translation from dense geometric correspondences.
Results and impact
The implementation is designed around limited real supervision, using about 600 real images per object together with synthetic view generation. The paper reports evaluation on LINEMOD, LM-O, and YCB-Video with standard 6D pose metrics such as ADD(-S) and AUC. For deployment-oriented robotics and inspection, the main value is that new object categories can be added with much less real pose annotation than fully supervised pose pipelines.