VeinTr: Robust end-to-end full-hand vein identification with transformer

Hand vein recognition has attracted significant interest as a non-contact, hard-to-spoof biometric modality, but the field has been dominated by methods that extract local vein patterns using hand-crafted filters or convolutional networks with limited receptive fields. Global vein topology—how vein branches interconnect across the entire hand—is a powerful discriminator that these local approaches cannot fully exploit. VeinTr addresses this gap by introducing a transformer-based architecture where self-attention layers directly model long-range relationships between vein regions anywhere on the hand. The model ingests full-hand near-infrared images and produces an identity embedding in a single forward pass, with no separate vein segmentation or feature extraction step. The attention maps learned by the model align well with anatomically meaningful vein junction points, lending interpretability to the predictions. Evaluated on standard full-hand vein databases, VeinTr sets a new state of the art in equal error rate and rank-1 identification accuracy, while remaining robust to variations in hand positioning, skin tone, and illumination, as reported in The Visual Computer (2024).
Problem setting
Vein pattern recognition is a contactless biometric modality with high security and liveness guarantees, but existing methods rely on hand-crafted vein feature extractors or CNNs that capture only local patterns, limiting accuracy on full-hand images where global topology carries discriminative information. VeinTr proposes an end-to-end transformer architecture for full-hand vein identification that uses self-attention to model long-range dependencies between vein branches across the entire hand image. The model is trained on near-infrared full-hand vein images and evaluated against CNN and traditional feature-based baselines.
The figures below collect representative visual evidence from The Visual Computer, 40(10):7015–7023.
Method and visual evidence
The visuals highlight full-hand near-infrared vein inputs, the transformer identification pipeline, and recognition results across CASIA, TPV, and PLUSVein. Author portraits and metadata pages are intentionally excluded from the page assets.
VeinTr pipeline: full-hand NIR input, convolutional local feature extraction, residual blocks, transformer attention, and probe-to-database matching.
Example full-hand vein samples from the CASIA, TPV, and PLUSVein datasets used in evaluation.
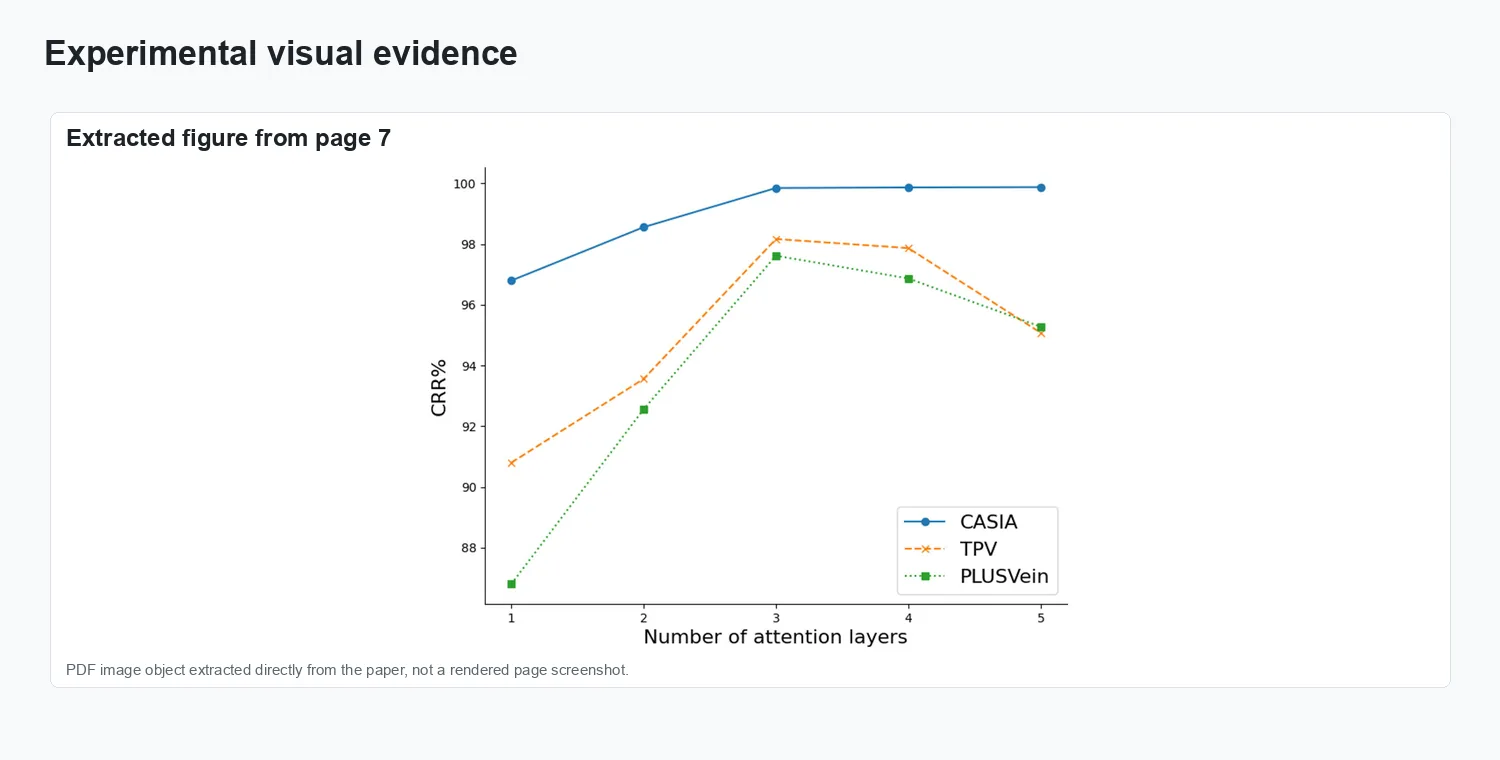
Ablation on the number of attention layers, reported as correct recognition rate across three datasets.
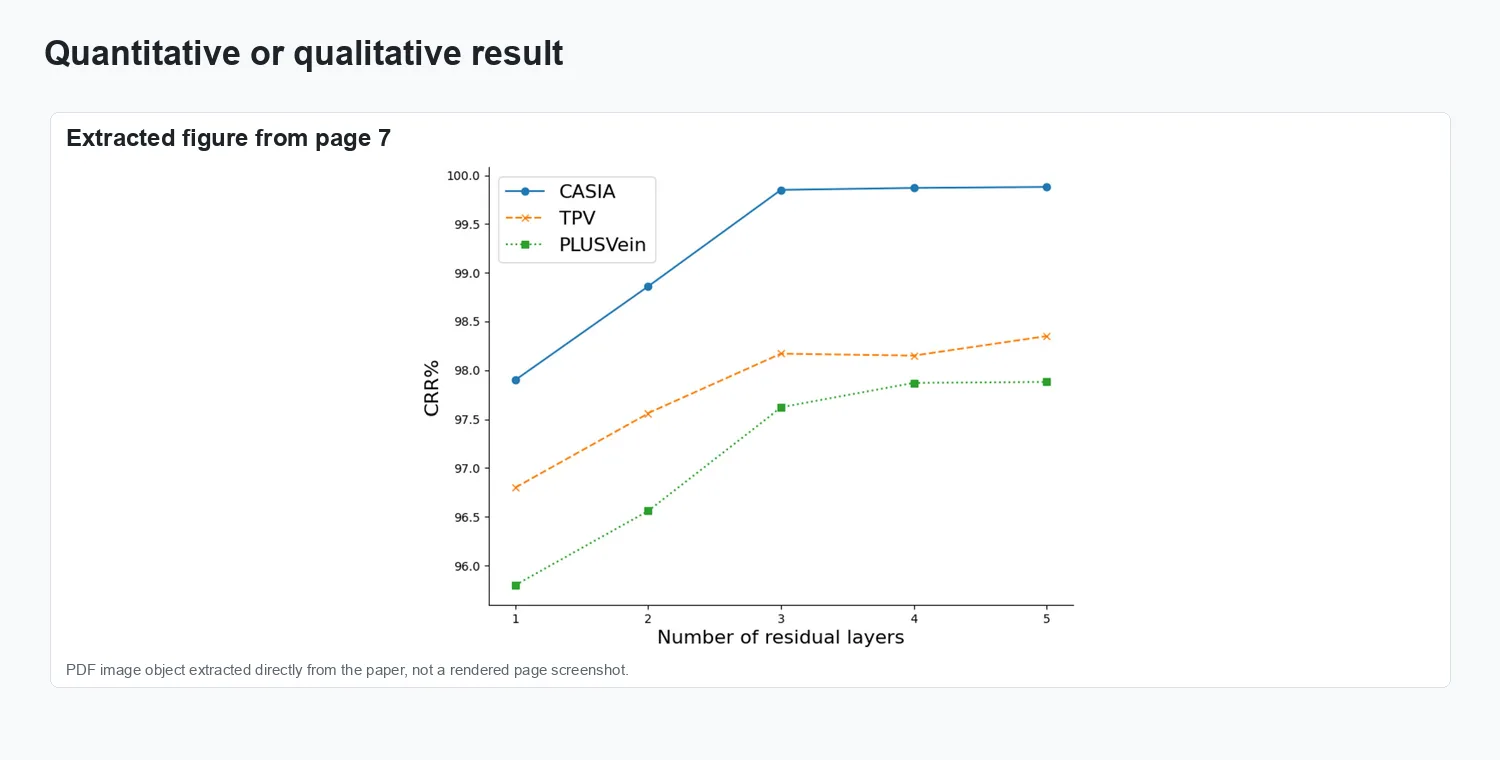
Ablation on the number of residual layers, showing the effect of the local feature encoder depth.
Results and impact
The evaluation reported in The Visual Computer, 40(10):7015–7023 is summarized through the figures above.