DeSC: Learning Deep Semantic Descriptor for NeRF Registration
DeSC studies NeRF-to-NeRF registration: given two independently trained NeRF models of the same object or scene, estimate the rigid transformation between their coordinate frames. This is useful when large scenes are reconstructed as separate NeRF blocks, when camera poses are unavailable or noisy, or when new image subsets need to be integrated without retraining one monolithic NeRF.
Problem setting
Classical point cloud registration tools can be applied by sampling points from NeRF, but those point clouds are often noisy and artifact-prone because density estimation may be inaccurate. Pure photometric optimization has the opposite problem: it can fail on textureless, symmetric, or low-overlap cases. DeSC takes another route by using NeRF’s internal view-independent embeddings, which carry both geometric and appearance information but are less tied to a single rendered view.
The main observation is that independently trained NeRFs do not share an identical embedding space, yet corresponding regions of the same scene still preserve similar local relations. DeSC therefore learns descriptors from local NeRF patches instead of matching raw sampled geometry or final rendered color alone.
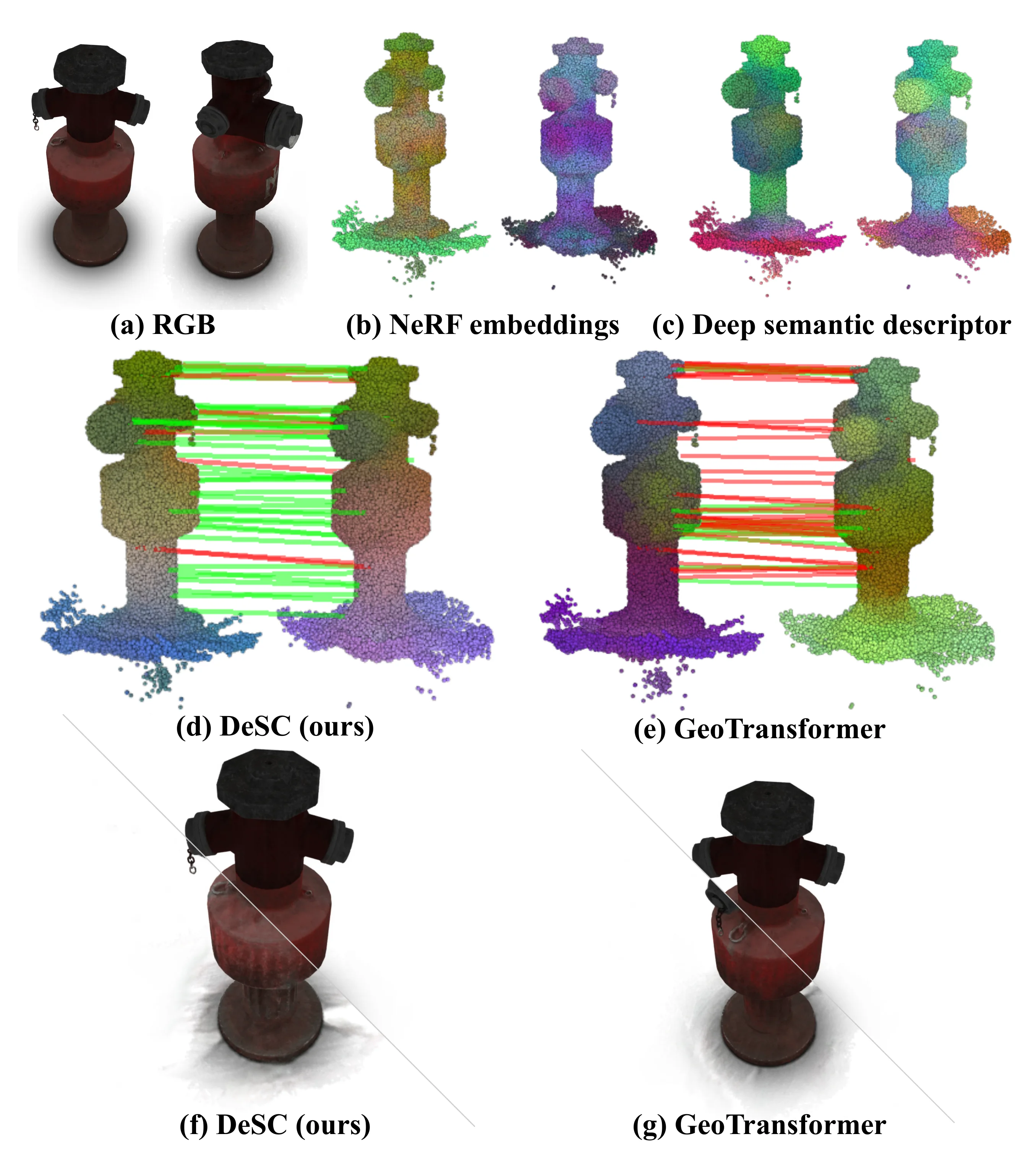
Feature motivation. Raw NeRF embeddings can be inconsistent across frames, while the learned deep semantic descriptor produces more stable local features, better correspondences, and more accurate NeRF alignment.
Algorithm principle
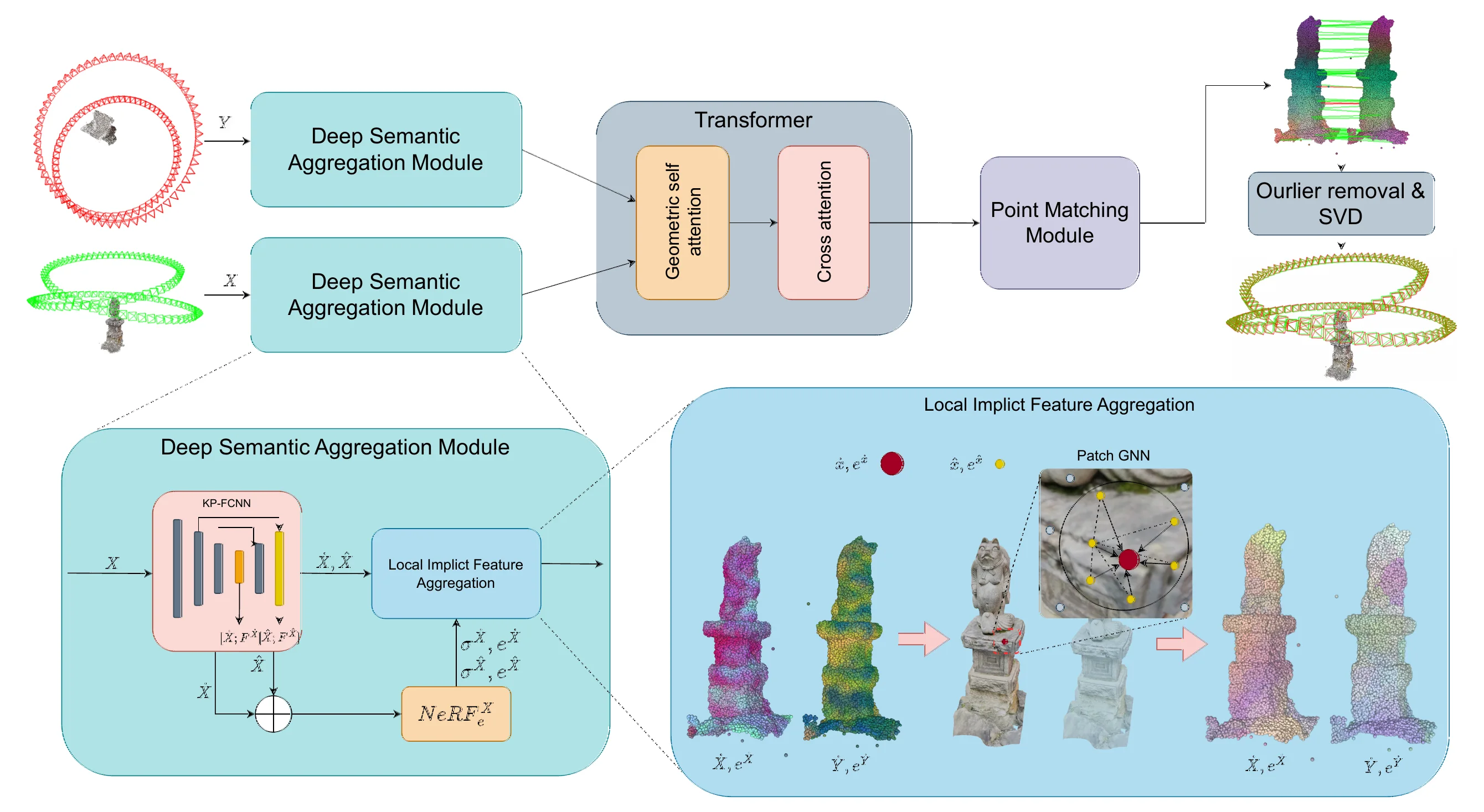
The pipeline first samples a NeRF-derived point cloud using the occupancy grid and density threshold. KP-FCNN builds multi-level geometric features and downsampled point sets. For each sparse point, DeSC forms a local patch from nearby dense points, queries the NeRF for view-independent embeddings, and enriches them with color and density through photometric encoding.
The core module is the Deep Semantic Aggregation Module (DSAM). It applies a texture-aware graph convolution over each local patch, using local high-frequency texture weights so nearby points with distinctive implicit features are emphasized. The resulting deep semantic descriptors are fused with geometric features, then passed through self-attention and cross-attention Transformer blocks. A point matching module produces correspondences, outliers are removed, and the final relative pose is estimated by SVD.
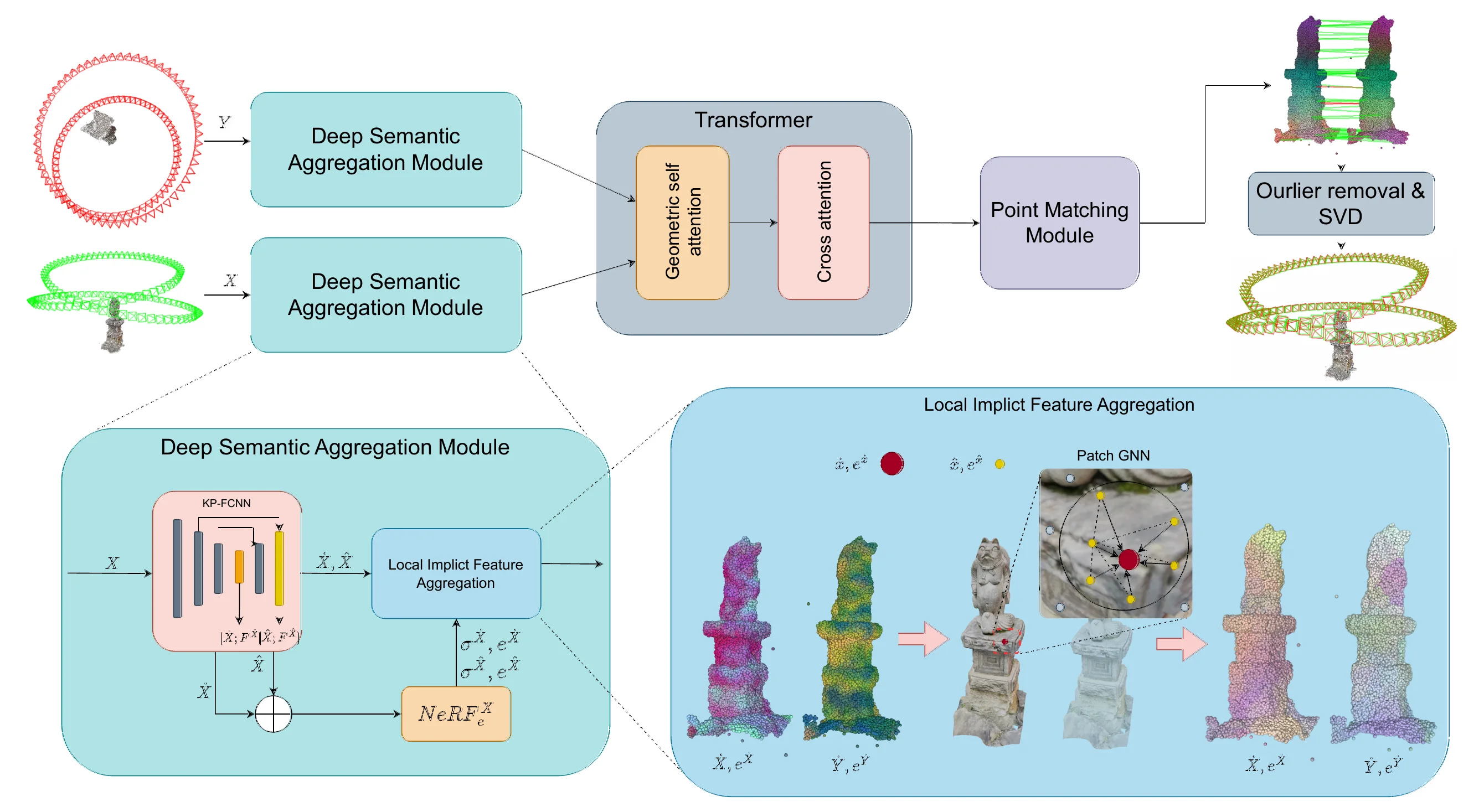
Method overview. DeSC extracts geometric and implicit NeRF features, aggregates local semantic descriptors with graph convolution, exchanges context with a Transformer, and estimates the final transformation from matched points.
Training objective
DeSC uses a coarse-to-fine correspondence pipeline with overlap-aware and matching losses, and adds a density-aware photometric consistency loss (DPCL). DPCL encourages descriptors to respect the photometric consistency of corresponding NeRF regions while remaining robust to noisy sampled geometry. The ablation in the final manuscript studies DSAM, photometric encoding (PE), local high-frequency texture weights (LHTW), and DPCL separately.
Results
On Objaverse, removing all DeSC modules reduces registration recall from 97.7% to 93.2%, and increases RRE from 2.57 degrees to 9.19 degrees. Removing DPCL alone also drops registration recall from 97.7% to 96.9%, showing that the photometric consistency term helps make the learned descriptor more reliable.
The revised manuscript also evaluates real and large-scale scenes. On DTU, DeSC reports the highest registration recall at 30%, 50%, and 80% overlap: 90.6%, 95.3%, and 97.9%. On LLFF, the corresponding values are 91.0%, 94.2%, and 98.1%. On Mip-NeRF360, DeSC reaches 88.1%, 90.9%, and 95.3%, with particularly clear gains in the 30% low-overlap setting.
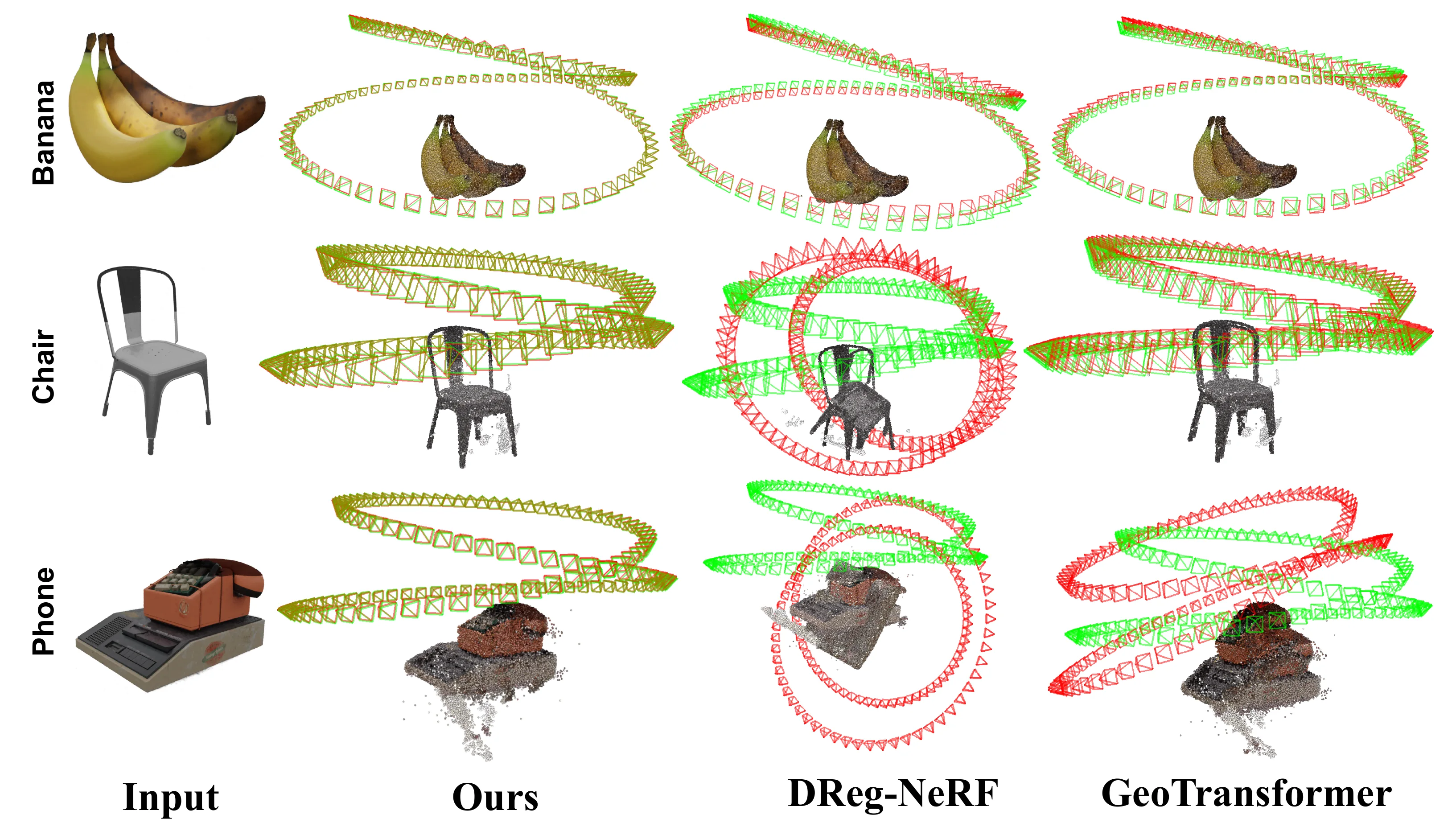
Objaverse qualitative comparison. The visualized NeRF geometry and camera poses show that DeSC is less affected by noisy high-density artifacts in empty space.

Real-scene comparison at 30% overlap. DeSC aligns DTU, LLFF, and Mip-NeRF360 examples more closely than DReg-NeRF and VF-NeRF in these low-overlap cases.

Overlap robustness. Qualitative examples at 30%, 50%, and 80% overlap show that the learned descriptor remains effective as shared visual support decreases.
Limitation
The method is designed for NeRF-style implicit representations and does not directly apply to explicit 3D Gaussian Splatting, voxel grids, or hash-based representations without adaptation. The paper also notes a symmetry failure mode: if object geometry and texture are highly symmetric, the learned features may still produce visually plausible but metrically incorrect alignments.
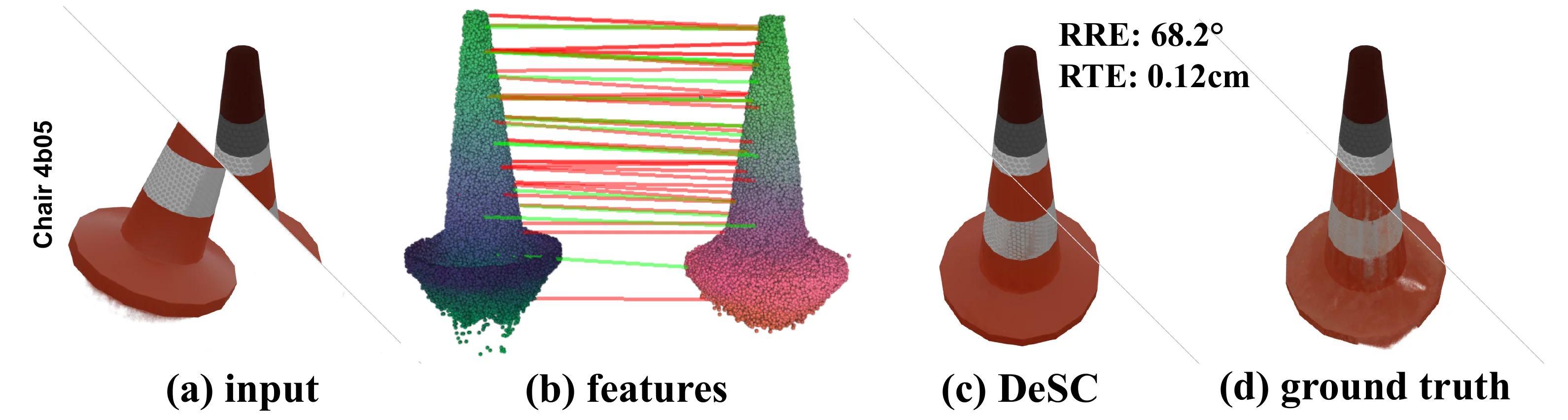
Failure case. Strong symmetry can lead to incorrect correspondences even when the visual alignment appears reasonable.